netkeiba のデータをスクレイピングして LOD 化する(7)

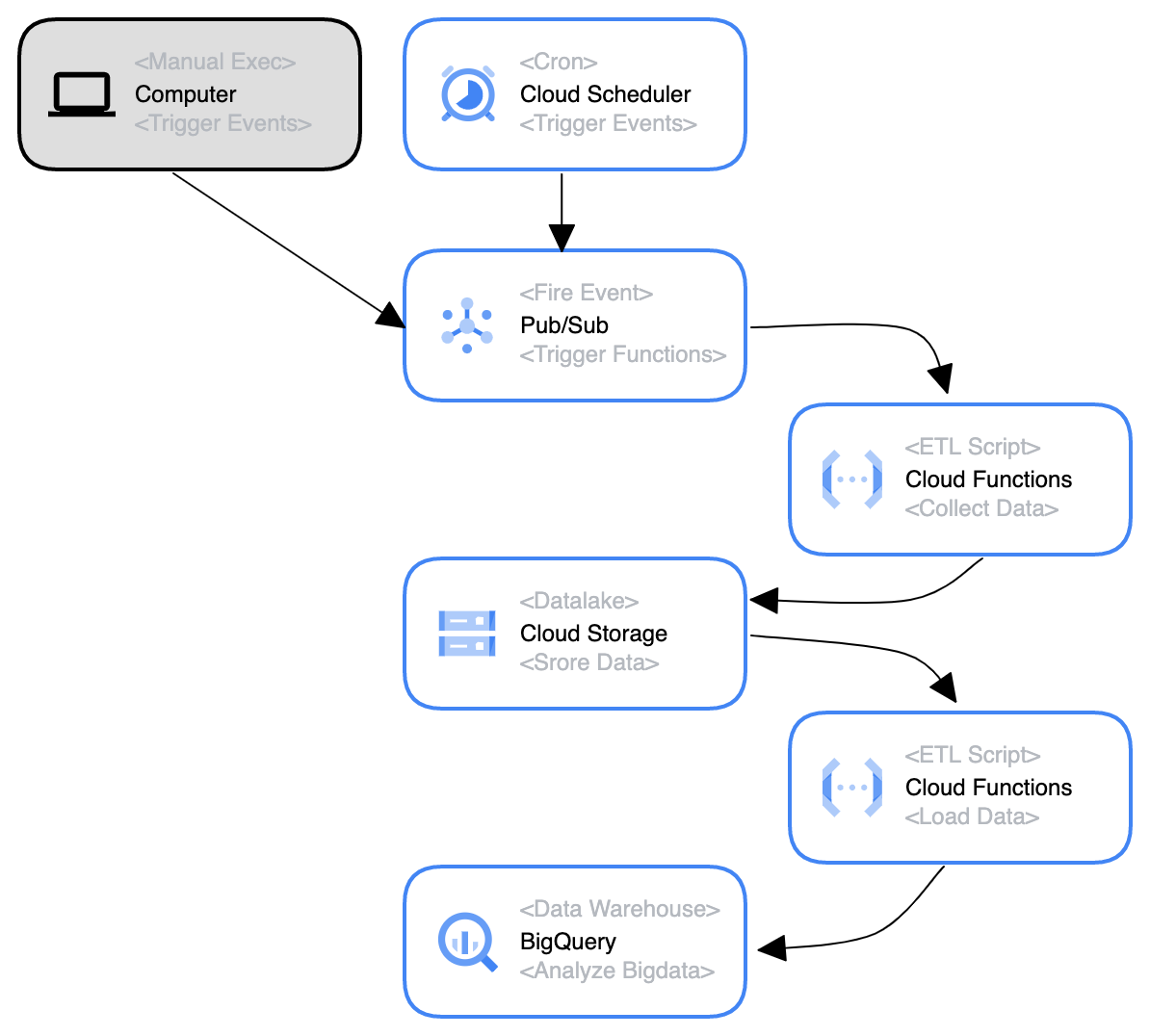
ML4Keiba に関する昨年の記事でも書いたように、ローカルだけでなくクラウド側にデータを保存し、それらをクラウド上の DB におさめて分析あるいはサービス提供できるようにしたいと考えている。
そんな折、以下の書籍を読む機会があり、そこでおおよその方向性がつかめたのでそれをまとめる。
一言で言えば、 Cloud Functions x GCS x BigQuery で DWH をつくる構想 といったところだろうか。
ML4Keiba としてデータを集めるのはいいが、その後についてきちんと考えをまとめていなかった。 マイルストーンというほど定かではないが、現在考えているいろいろなことをメモとして残す。
What までは書いてあるが、実際の具体的な How については自分の頭の中にあるだけだ。 これもどこかきちんと出力しておきたいが……また別の問題が生じるかもしれないので、後々考えることにする。
まだ zenn.dev に記事としてまとめることは出来ていないが,着々と自動化処理が作成できてきた.
一方で,エラーに関してもエッジケースが現れたのでその例外処理もプチプチやっていく.
JSON-LD のコンテキストもどうにか定義し,半信半疑だった API Gateway を活用したサーバ負荷回避 リクエスト制限の回避も実現できた.
これでようやくスクレピングによるデータ収集が始められる.
今回得た知見は,後ほど Zenn にまとめることとする.
前回はスクレイピング効率を高めるためにプロキシサーバを作ろうという試みを行なって終わった. 今回は具体的にどのようにデータを集めるか検討する.
python でデータを扱うにあたり,Notebook を使わない選択肢はないだろう. Google が提供する Colaboratory を使って,「下書き」的にコードを書いていく.
改めて,Netkeiba からスクレイピングをやっていく. Python でやるのは,リクエストに間隔を開ける都合上,多少時間がかかっても問題がないことや,DataFrame 系の資産を使い回せることが利点として挙げられる
https://github.com/Ningensei848/ml4keiba